
MIT researchers have developed PClean, a groundbreaking automated data cleaning AI system that transforms how data professionals handle corrupted information. This innovative probabilistic programming for data quality solution addresses the persistent challenges of typos, duplicates, missing values, and inconsistencies that plague databases worldwide.
Industry surveys reveal that data scientists spend up to 25% of their time on data cleaning tasks. What makes PClean stand out among AI-powered data cleaning tools is its ability to apply common-sense reasoning to complex data problems. Unlike conventional approaches, PClean leverages Bayesian data cleaning technology to make intelligent decisions when faced with ambiguity.
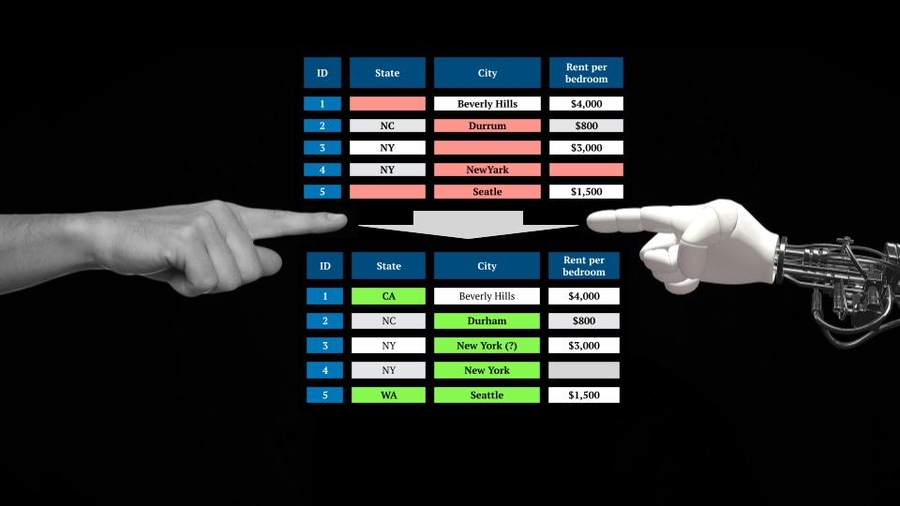
Consider a real estate database where someone lists their residence as "Beverly Hills" without specifying the state. With multiple locations sharing this name across California, Florida, Missouri, Texas, and even a Baltimore neighborhood, how can the system determine the correct one? PClean's sophisticated machine learning data preprocessing capabilities analyze contextual clues like rental prices to make educated inferences about the most likely location.
"Traditional programming requires explicit step-by-step instructions, but PClean operates more like consulting with a knowledgeable colleague," explains Alex Lew, lead author and PhD student in MIT's Department of Electrical Engineering and Computer Science. "You can provide background knowledge and hints, allowing the system to apply contextual understanding similar to human reasoning."
The research team, including Monica Agrawal, David Sontag, and Vikash K. Mansinghka, has created a solution that addresses a critical business need. As David Pfau from DeepMind noted, most business data exists in relational databases and spreadsheets, making AI-powered data cleaning tools essential yet underdeveloped compared to other AI applications.
What Makes PClean Revolutionary?
PClean builds upon decades of research in probabilistic computing, delivering three key innovations that set it apart from existing data cleaning solutions:
First, its expressive scripting language allows users to encode domain-specific knowledge, enabling the system to understand context in ways similar to human experts. Second, PClean employs a sophisticated two-phase inference algorithm that processes records individually before revisiting and refining its judgments. Finally, a custom compiler generates optimized code, allowing the system to process databases with millions of records efficiently.
Remarkably, PClean requires only about 50 lines of code to outperform existing benchmarks in both accuracy and runtime. For perspective, this is half the code needed for a simple mobile game and a fraction of what's required for complex applications like Minecraft.
In a compelling demonstration, PClean processed the 2.2 million-row Medicare Physician Compare National dataset in just seven-and-a-half hours, identifying over 8,000 errors with more than 96% accuracy when verified manually.
Benefits and Considerations
By automating data cleaning processes, PClean significantly reduces the resources companies dedicate to data preparation. However, the researchers acknowledge that such powerful technology raises privacy concerns, particularly regarding potential de-anonymization when combining information from multiple sources.
"We need stronger data and privacy regulations to address these challenges," says Mansinghka. "Unlike machine learning alternatives, PClean offers transparency in its decision-making process, allowing users to understand and control how data is processed."
The team is already exploring applications in journalism, humanitarian work, and election monitoring, hoping to free data scientists to focus on more meaningful tasks rather than tedious data cleaning.

