
Despite the remarkable achievements of neural networks, their internal workings remain largely enigmatic to researchers. While we can program these artificial intelligence systems to learn, comprehending their decision-making processes resembles solving an intricate puzzle with numerous missing pieces and complex patterns that defy easy interpretation.
When an AI model attempts to classify images, it may face not only well-documented adversarial attacks but also a newly identified, more subtle failure mode discovered by MIT researchers: "overinterpretation." This phenomenon occurs when algorithms make high-confidence predictions based on details that appear meaningless to humans—such as random patterns or image borders—raising significant concerns about AI reliability.
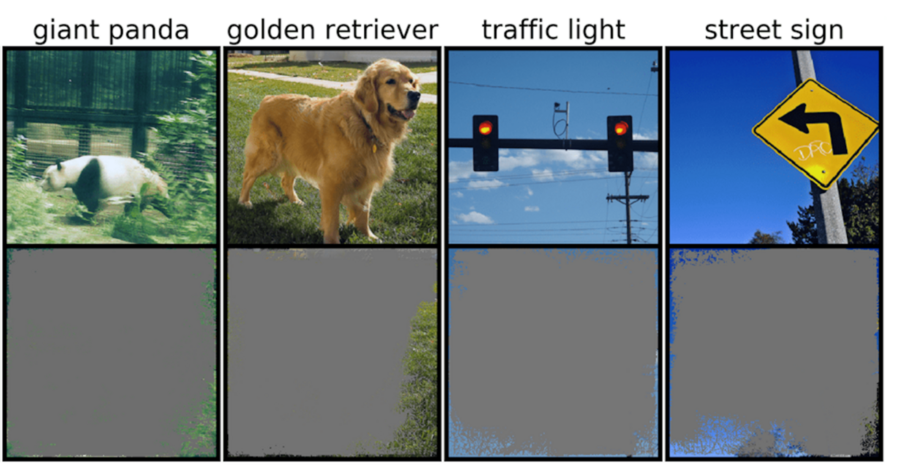
The implications of overinterpretation are particularly troubling for high-stakes applications requiring split-second decisions, including autonomous vehicles and medical diagnostics where immediate attention is crucial. Self-driving cars, for instance, depend on systems that must accurately interpret their surroundings and make rapid, safe decisions. The research revealed that these networks often rely on specific backgrounds, edges, or sky patterns to classify traffic signals and street signs, regardless of the actual content in the image.
The MIT team discovered that neural networks trained on popular datasets like CIFAR-10 and ImageNet consistently demonstrated overinterpretation tendencies. Remarkably, models trained on CIFAR-10 maintained confident predictions even when 95% of input images were obscured, leaving only fragments that would appear nonsensical to human observers.
"Overinterpretation represents a fundamental dataset problem caused by meaningless signals embedded within training data. These high-confidence predictions persist despite images containing less than 10% of the original content, typically in unimportant regions like borders. What's particularly concerning is that while these images appear meaningless to humans, AI systems classify them with remarkable confidence," explains Brandon Carter, MIT Computer Science and Artificial Intelligence Laboratory PhD student and lead author of the research paper.
Deep-image classifiers have become ubiquitous across numerous applications. Beyond medical diagnosis and autonomous vehicle technology, these systems are employed in security, gaming, and even consumer applications that identify everyday objects. The underlying technology processes individual pixels from thousands of pre-labeled images, enabling the network to "learn" through pattern recognition.
The challenge of image classification is compounded by machine learning models' tendency to latch onto these subtle, meaningless signals. When trained on datasets like ImageNet, classifiers can generate seemingly reliable predictions based entirely on these irrelevant features.
While these nonsensical signals can cause model fragility in real-world applications, they remain technically valid within the dataset context. This paradox means that overinterpretation cannot be detected through conventional evaluation methods based on accuracy metrics alone.
To uncover the rationale behind a model's prediction, the researchers developed an innovative approach. Starting with the complete image, they repeatedly asked: "What elements can be removed while maintaining the same prediction?" This process progressively obscures the image until identifying the minimal subset that still triggers a confident decision.
This methodology could also serve as a valuable validation tool. For instance, when testing an autonomous vehicle's stop sign recognition system, one could identify the smallest input subset that the system classifies as a stop sign. If this subset consists of irrelevant elements like tree branches or specific lighting conditions rather than actual stop sign features, it indicates potential safety concerns in real-world deployment.
While it might seem natural to blame the models themselves, the research suggests that datasets are more likely the root cause. "We need to explore how we can modify datasets to enable models that more closely approximate human classification thinking. This approach would hopefully lead to better generalization in real-world scenarios like autonomous driving and medical diagnosis, preventing these nonsensical behaviors," notes Carter.
This might necessitate creating datasets in more controlled environments. Currently, most training images are simply extracted from public domains and classified. However, for effective object identification, it may be essential to train models using objects presented against neutral, uninformative backgrounds.
This research received support from Schmidt Futures and the National Institutes of Health. Carter authored the paper alongside Siddhartha Jain and Jonas Mueller, scientists at Amazon, and MIT Professor David Gifford. The team presented their findings at the 2021 Conference on Neural Information Processing Systems.

