
The rapid expansion of artificial intelligence applications on mobile devices has created an urgent need for more efficient deep learning model compression techniques. As smartphone users demand faster performance and longer battery life, MIT researchers have pioneered a groundbreaking approach to reducing neural network size without sacrificing accuracy.
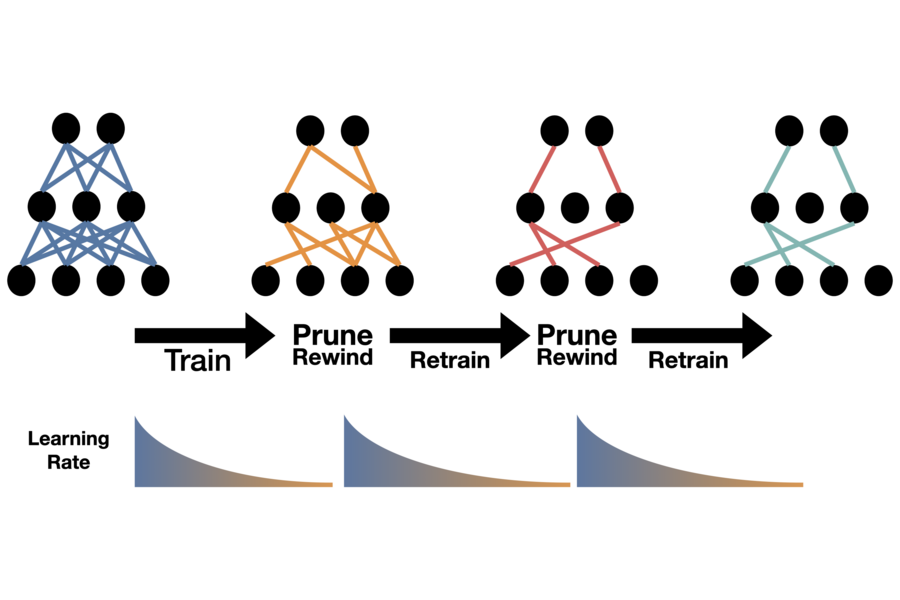
The innovative method, surprisingly straightforward, was recently unveiled through a social media announcement: First train the AI model completely, then systematically eliminate its weakest connections, followed by retraining at the accelerated early training rate. This process repeats until the model reaches the desired compact size for mobile deployment.
"The simplicity is revolutionary," explains Alex Renda, a doctoral candidate at MIT. "Traditional approaches to neural network pruning involve unnecessarily complex algorithms that often yield suboptimal results."
Renda presented these findings at the virtual International Conference of Learning Representations (ICLR). The research team includes fellow MIT PhD student Jonathan Frankle and Assistant Professor Michael Carbin, all affiliated with the prestigious Computer Science and Artificial Intelligence Laboratory.
This breakthrough in AI model pruning for mobile devices builds upon the researchers' award-winning Lottery Ticket Hypothesis, which demonstrated that deep neural networks could maintain performance with just 10% of their connections when the optimal subnetwork is identified early in training. This discovery comes at a critical time, as the computational resources and energy required for training increasingly large deep learning models continue to grow exponentially, creating environmental concerns and accessibility barriers for researchers outside major tech corporations.
The inspiration for exploring improved compression methods emerged from previous work on neural network efficiency. While pruning algorithms have existed for decades, the field experienced renewed interest following the success of neural networks in image classification tasks. As models expanded with additional layers to enhance performance, the need for effective size reduction techniques became increasingly apparent.
Song Han, now an MIT professor, emerged as a pioneer in this domain with his development of AMC (AutoML for model compression), which remains the industry standard. Han's approach automatically removes redundant neurons and connections, followed by retraining to restore accuracy.
Building upon Han's work, Frankle proposed in an unpublished paper that results could be enhanced by rewinding the pruned model to its initial parameters and retraining at the faster, early-stage rate.
In their current ICLR presentation, the researchers discovered that the model could be rewound to its early training rate without adjusting any parameters. While all pruning methods experience some accuracy reduction as models shrink, this new approach consistently outperformed both Han's AMC and Frankle's weight-rewinding methods across various compression levels.
The exact reasons behind this technique's effectiveness remain unclear, with the researchers leaving this question for future investigation. However, they emphasize that the algorithm is as straightforward to implement as other pruning methods, without requiring extensive parameter tuning.
"This represents the ideal pruning algorithm," Frankle declares. "It's universally applicable, remarkably clear in its implementation, and elegantly simple in its design."
Meanwhile, Han has expanded his focus beyond compression to developing methods for creating inherently small, efficient models from the outset. His newest approach, "Once for All," also debuted at ICLR. Regarding the MIT team's breakthrough, Han notes: "The evolution of pruning and retraining techniques is encouraging, as it democratizes access to high-performing AI applications across diverse user populations."
Funding for this research was provided by the Defense Advanced Research Projects Agency, Google, MIT-IBM Watson AI Lab, MIT Quest for Intelligence, and the U.S. Office of Naval Research.

